



студент
Красноярский край, Россия
Россия
УДК 614.84 Пожарная охрана. Опасность пожара. Пожары
В статье представлены промежуточные результаты разработки специализированного умного помощника для нужд пожарной охраны. Исследование посвящено решению проблемы поиска релевантной информации в нормативно-технической документации и базах данных для упрощения работы с ней. Авторами проанализированы возможности существующих готовых нейросетевых моделей для задач поиска по документам (Embedding). Установлено, что их прямое применение в узкой профессиональной области пожарной безопасности ограничено из-за низкой точности, вызванной недостатком специализированного контекста и терминологии. В качестве решения предложен подход к созданию собственной нейронной сети, адаптированной под специфику предметной области
умный помощник пожарного, пожарная охрана, нейронные сети, искусственный интеллект, обработка естественного языка
В условиях современного оперативно-служебного ландшафта работа с информацией остается одним из наиболее трудоемких и критически важных процессов [1]. Специалисты, в частности в сфере пожарной охраны, ежедневно сталкиваются с колоссальным и непрерывно растущим потоком данных: от постоянно обновляющихся нормативно-правовых актов, причем проблема состоит не только в их массовом количестве, но и в противоречии документов друг другу.
Однако эта задача наталкивается на системные ограничения. Во-первых, в полевых условиях или на объектах с нарушенной инфраструктурой доступ к актуальным базам данных через интернет может быть невозможен или нестабилен. Во-вторых, даже при его наличии, классический поиск в массиве цифровых документов требует времени и определенных навыков. В-третьих, традиционная опора на бумажные носители — копии нормативно-правовых актов, распечатанные инструкции — делает процесс поиска информации неприемлемо медленным для реагирования в режиме реального времени.
Возникает объективная необходимость в качественно новом инструменте — интеллектуальном помощнике, который мог бы радикально сократить когнитивную и временную нагрузку на специалиста [2-3]. Такой ассистент должен не просто хранить документы, а понимать естественно-языковый запрос человека, мгновенно анализировать локальную базу знаний, сформированную из утвержденных нормативно-правовых актов в области пожарной безопасности, и предоставлять точный, обоснованный выдержками из источников ответ. Это позволит перейти от трудоемкого поиска к мгновенному получению решения, обеспечив тем самым новое качество оперативного принятия решений в экстренных ситуациях. Разработка подобной системы и представляет собой цель настоящего исследования.
Проведенный ранее эксперимент по использованию русскоязычной модели Saiga LLM [4] выявил ее ограниченную применимость для решения узкоспециализированных задач. Если на общих вопросах модель показала работоспособность, то тестирование на точных, фактографических запросах из области пожарной безопасности продемонстрировало большое количество аномалий (Аномалия – ошибки искусственного интеллекта) (рис. 1). В ходе апробации лишь 3 из 10 сгенерированных ответов соответствовали запросу, что указывает на высокую вероятность генерации недостоверных данных, также, данная модель имеет слишком большой вес (Веса модели - это фундаментальные, обучаемые параметры в нейронной сети, которые преобразуют входные данные), что делает ответ продолжительно долгим (около 5-7 минут). Таким образом, Saiga LLM не отвечает требованиям исследования.

Рис. 1. Аномалия модели
Для преодоления выявленных ограничений архитектура системы была существенно модернизирована. Первоначальный прототип, реализованный в среде RenPy [4], был заменен на автономное клиент-серверное приложение в формате исполняемого (.exe) файла. Данный переход обеспечил необходимую гибкость и производительность для проведения дальнейших экспериментов.
В новой архитектуре была реализована классическая схема RAG (Retrieval-Augmented Generation) [5]. В ее основе лежат две независимые нейронные сети:
- Модель эмбеддингов (Embedding model), ответственная за семантическое векторное представление текста [6]. Ее задача — преобразовать корпус нормативных документов и пользовательский запрос в числовые векторы (эмбеддинги), что позволяет эффективно находить релевантные фрагменты текста по смысловой близости.
- Языковая модель (LLM model) [7], отвечающая за генерацию итогового ответа. Она получает исходный запрос пользователя и найденные релевантные контексты (chunks) из базы знаний и формирует на их основе связный, фактологически точный текст.
Для обеих ролей была выбрана модель Qwen. Критерием выбора послужил оптимальный баланс между качеством выходных данных (как для создания эмбеддингов, так и для генерации) и вычислительной эффективностью (размером модели), что является важным для потенциального развертывания системы на ограниченных аппаратных ресурсах.
На текущем этапе разработки был выявлен системный недостаток, ограничивающий функциональность системы в целевой русскоязычной среде. Несмотря на заявленную мультиязычность, выбранная модель Qwen продемонстрировала недостаточную компетенцию в обработке русскоязычных текстов.
Данное ограничение проявилось на двух уровнях архитектуры:
- На уровне извлечения информации: Модель эмбеддингов (Embedding model) генерирует векторные представления для русскоязычных документов и запросов с низкой семантической точностью. Это приводит к некорректной работе механизма поиска релевантных контекстов — система часто не находит ключевые документы или извлекает фрагменты, не соответствующие сути запроса.
- На уровне генерации ответа: Языковая модель (LLM model), получая даже корректный контекст, формирует ответы с фактологическими ошибками. Более того, наблюдаются случаи кодового смешения, когда часть ответа генерируется на китайском языке, что является прямым следствием смещения распределения вероятностей модели в сторону основного языка ее предобучения.
Таким образом, языковой барьер модели Qwen приводит к каскадному сбою всей RAG-архитектуры: неточный поиск усугубляется некорректной генерацией.
Опираясь на результаты предыдущих неудачных экспериментов с мультиязычными моделями общего назначения, был сформулирован принципиально иной подход — разработка собственной специализированной нейронной сети. Ключевая гипотеза заключается в том, что узкопредметная область пожарной безопасности, характеризующаяся строго формализованным языком и ограниченным понятийным аппаратом, представляет собой более решаемую задачу для обучения, чем тонкая настройка универсальной модели с ее избыточной сложностью и смещенными распределениями данных.
Для реализации данного подхода была разработана и применена комбинированная двухэтапная методология обучения:
- Контролируемое обучение на размеченных диалоговых данных (Supervised Fine-Tuning, SFT). Был создан специализированный датасет, содержащий 4000 триплетов «вопрос-ответ», отражающих вопросы, касающиеся пожарной охраны. Каждый вопрос был снабжен тремя вариативными, но семантически эквивалентными ответами, что позволяет модели абстрагироваться от конкретной формулировки и усвоить инвариантную семантику запроса, повышая тем самым ее работоспособность. Датасет был разделен на обучающую, валидационную и тестовую выборки в стандартной пропорции для объективной оценки обобщающей способности модели.
Обучение с подкреплением на основе документов (Document-based Reinforcement Learning). Для обработки запросов, выходящих за пределы подготовленных диалоговых пар, был реализован механизм, при котором модель не генерирует ответ напрямую, а выполняет семантический поиск в предоставленном корпусе нормативных документов (рис. 2,3). Важным решением на этом этапе стал отказ от мультиязычных эмбеддинг-моделей в пользу специализированной русскоязычной модели ruBERT [8]. Ее выбор обусловлен глубоким предобучением на русскоязычных текстах, что гарантирует высокое качество создания семантических векторных представлений (эмбеддингов) для терминологически насыщенных документов и запросов, решая тем самым ключевую проблему предыдущих этапов — низкое качество поиска.
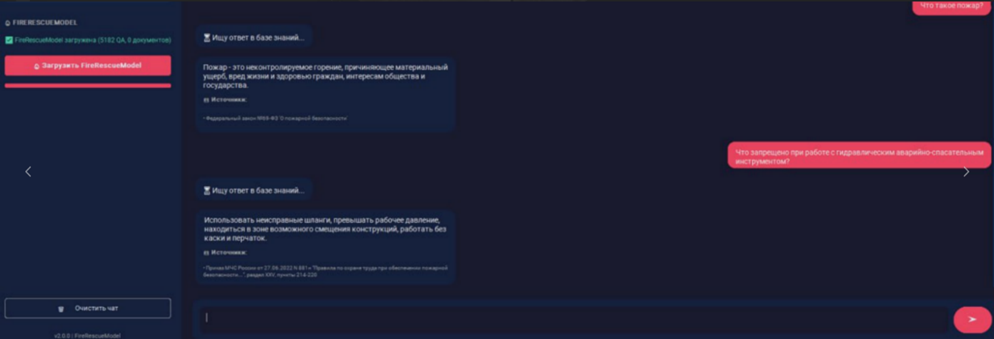
Рис. 2. Ответ модели согласно нормативно-правовым документам
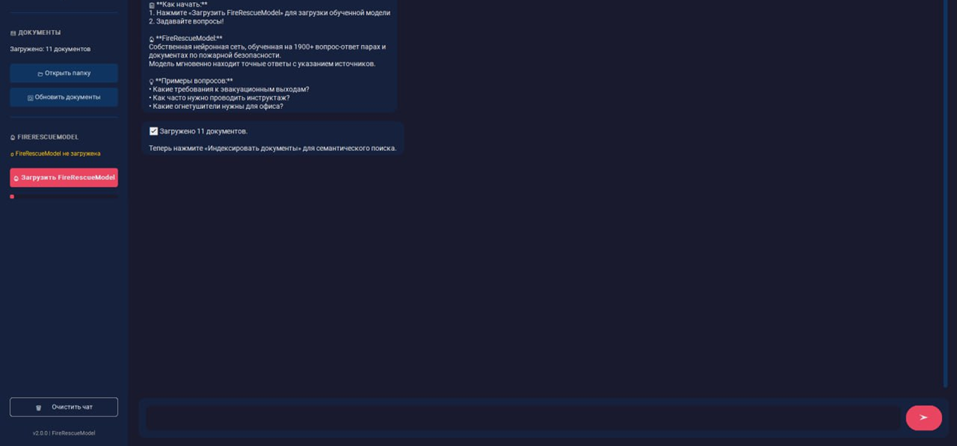
Рис. 3. Интерфейс умного помощника
Предложенная архитектура демонстрирует полное соответствие ключевым требованиям, сформулированным в рамках исследования.
Во-первых, система обладает высокой вычислительной эффективностью. В её основе лежит предобученная и дообученная модель (ruBERT для поиска и собственная обученная LLM для генерации), что исключает необходимость ресурсоёмкого обучения с нуля на каждом этапе развёртывания. Основная нагрузка приходится на этап инференса (логического вывода), что позволяет системе функционировать на стандартном аппаратном обеспечении без использования мощных GPU-кластеров. Это необходимо для потенциального внедрения в условиях пожарных частей или на мобильных командных пунктах.
Во-вторых, достигнута приемлемая оперативность работы. Время формирования ответа на типовой запрос составляет от 10 до 30 секунд. Данный интервал является удовлетворительным для большинства сценариев аналитической и подготовительной работы, что подтверждает практическую применимость системы в реальных, хотя и не экстремально срочных, условиях.
В-третьих, система обладает принципиальной способностью к адаптивному дообучению [9]. Это реализуется по двум основным направлениям:
- Коррекция ошибок: При выявлении некорректного ответа у администратора системы появляется возможность предоставить модели корректную пару «вопрос-ответ». Эта пара добавляется в тренировочный набор для последующих циклов дообучения, что позволяет системе эволюционировать и минимизировать повторение аналогичных ошибок в будущем.
- Расширение базы знаний: Система допускает масштабирование как базы документов для семантического поиска, так и диалогового датасета. Загрузка новых массивов вопросов и ответов с последующим дообучением модели позволяет постоянно повышать её охват и точность, адаптируя помощника к изменениям в нормативной базе или появлению новых типовых оперативных задач.
Таким образом, разработанное решение не только решает конкретную проблему языкового барьера, но и удовлетворяет системным критериям эффективности, скорости и способности к непрерывному развитию, заложенным в методологию исследования.
Основным вектором дальнейшего развития данного исследования станет качественное и количественное расширение предметной области интеллектуального помощника.
В краткосрочной перспективе работа будет сосредоточена на горизонтальном масштабировании в рамках сферы пожарной охраны. Планируется систематическое пополнение корпуса документов, на которых обучается и работает модель, за счет включения новых категорий нормативных, справочных и оперативных материалов. Это позволит охватить более широкий спектр специализированных направлений, таких как: профилактические проверки, расследование причин пожаров, тактика тушения специфических объектов (нефтехимические комплексы, высотные здания, объекты транспорта), применение специального оборудования и средства индивидуальной защиты. Целью данного этапа является превращение системы в универсального ассистента для всех основных служебных задач рядового и офицерского состава пожарной охраны.
В долгосрочной перспективе исследование нацелено на вертикальное расширение предметной области до масштабов всей пожарной безопасности.
1. Бакиров И. К., Хафизов Ф. Ш., Султанов Р. М. Проблемы применения нормативных документов по пожарной безопасности // Пожаровзрывобезопасность. 2014. №1. URL: https://cyberleninka.ru/article/n/problemy-primeneniya-normativnyh-dokumentov-po-pozharnoy-bezopasnosti (дата обращения: 12.01.2026).
2. Ямалтдинова, Э. И. Интеллектуальный виртуальный помощник / Э. И. Ямалтдинова, А. А. Барсукова // ТЕОРИЯ и ПРАКТИКА СОВРЕМЕННОЙ науки: сборник статей IV Международной научно-практической конференции, Пенза, 20 января 2021 года. – Пенза: "Наука и Просвещение" (ИП Гуляев Г.Ю.), 2021. – С. 49-51. – EDN XEQVCG.
3. Захарова, А. В. Интеллектуальный помощник в образовании / А. В. Захарова // Технологические перспективы человечества: материалы Всероссийской научной конференции студентов и молодых ученых, Йошкар-Ола, 11–12 мая 2023 года. – Йошкар-Ола: Поволжский государственный технологический университет, 2023. – С. 51-56. – EDN TWTEOK.
4. Шамсудинов, Г. Ю. Пример реализации системы нормативно-правовой поддержки специалистов пожарной безопасности с использованием искусственного интеллекта / Г. Ю. Шамсудинов // Сервис безопасности в России: опыт, проблемы, перспективы : Материалы Международной научно-практической конференции, Санкт-Петербург, 23 октября 2025 года. – Санкт-Петербург: Санкт-Петербургский университет государственной противопожарной службы МЧС России им. Героя Российской Федерации генерала армии Е.Н. Зиничева, 2025. – С. 130-132. – EDN BEKOSW.
5. Cuconasu F. et al. The power of noise: Redefining retrieval for rag systems //Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. – 2024. – С. 719-729.
6. Inglesfield J. E. A method of embedding //Journal of Physics C: Solid State Physics. – 1981. – Т. 14. – №. 26. – С. 3795.
7. Еремин, И. В. Методы и алгоритмы разработки интеллектуальных помощников на основе больших языковых моделей / И. В. Еремин, В. А. Храмова // Проблемы управления в социально-экономических и технических системах : Материалы XX Международной научно-практической конференции. Сборник научных статей, Саратов, 17–18 апреля 2024 года. – Саратов: Издательский центр "Наука", 2024. – С. 32-36. – EDN MEIVKK.
8. Олисеенко, В. Д. Эмбеддинги языковой модели RuBERT в задаче многоклассовой классификации постов пользователей в социальной сети / В. Д. Олисеенко, М. В. Абрамов // Международная конференция по мягким вычислениям и измерениям. – 2022. – Т. 1. – С. 45-48. – EDN ORADTX.
9. Тодаренко, В. П. Метод стохастических вариационных неравенств для дообучения моделей трансформеров / В. П. Тодаренко, И. В. Шарун // Прикладная математика и фундаментальная информатика : Материалы XV Международной молодежной научно-практической конференции с элементами научной школы, Омск, 19–24 мая 2025 года. – Омск: Омский государственный технический университет, 2025. – С. 143-144. – EDN AFBJVL.